结构体
RedisObject 是封装键值对的基本单元,每个对象都可以关联不同的底层数据结构体,这样设计的好处是可以根据具体场景,灵活使用合适的数据结构,此外,通过统一的对象结构体,Redis 还实现了通过引用计数共享对象、LRU/LFU 淘汰数据的功能。
redisObject 的基本结构定义在https://github.com/redis/redis/blob/7.2.4/src/server.h#L899:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
};redisObject->type
type 字段就是经常使用的数据库中键值对的“类型”,如常说的“字符串键”,“哈希键”等,源码中具体的枚举值和含义:
OBJ_STRING:值为0,表示字符串类型对象;OBJ_LIST:值为1,表示列表类型对象;OBJ_SET:值为2,表示集合类型对象;OBJ_ZSET:值为3,表示有序集合类型对象;OBJ_HASH:值为4,表示哈希类型对象
redisObject->encoding
encoding 为编码方式,表示当前对象具体使用哪种底层的数据结构,可能的枚举值和含义:
-
OBJ_ENCODING_RAW:表示当前对象指向的内容是一个普通的 SDS -
OBJ_ENCODING_INT:表示当前对象指针指向的是一个整数值
Redis 服务器启动时候,会默认创建从 0~OBJ_SHARED_INTEGERS=10000 个整数编码的对象,这些对象可以通过引用计数的方式实现复用共享。
OBJ_ENCODING_EMBSTR:表示使用的是嵌入式的SDS字符串
嵌入式的 SDS 字符串指的是 SDS 数据在内存中和 redisObject 紧密排列在一段连续的内存当中,普通 raw 编码的 redisObject 指向的 SDS 需要分别经过2次内存分配,embstr 编码的 redisObject 创建时候直接分配一块连续的内存空间,可以快速通过指针的前进后退定位到相邻的 SDS 内容。embstr 编码的 SDS 通常是只读状态的,一但对其内容进行修改,redis 会自动将其编码格式从 embstr 转换为 RAW。
-
OBJ_ENCODING_HT:表示当前对象指向的是一个字典 -
OBJ_ENCODING_ZIPMAP:旧有编码格式,不再使用 -
OBJ_ENCODING_LINKEDLIST:旧的编码格式,指使用链表底层编码,redis 7 以后不再使用 -
OBJ_ENCODING_ZIPLIST:表示使用压缩列表数据结构,redis 7 不再使用 -
OBJ_ENCODING_INTSET:表示指向一个整数集合数据结构 -
OBJ_ENCODING_SKIPLIST:表示指向一个跳跃表结构 -
OBJ_ENCODING_QUICKLIST:表示指向了一个快速列表数据结构 -
OBJ_ENCODING_LISTPACK:表示指向的是一个紧凑列表
type 和 encoding 对应关系
每种 type 会在底层灵活使用多种不同的 encoding 编码方式,通用的一个规律是:当需要保存的元素占用空间比较小或者子元素的数量比较少的时候,为了不浪费内存空间,redis 会自动选择更加节省内存的编码方式(如:ziplist 或者 listpack)来存放数据,当要存放的数据量比较大的时候,这时候读写效率的优先级就高于空间占用了,相应的,Redis 又会使用对读写比较友好的编码格式来存储数据了。
目前最新的 Redis 7.2.4 版本(https://github.com/redis/redis/tree/7.2.4)中不同 redisObject 和可能会用到的底层数据结构的对应关系如图:
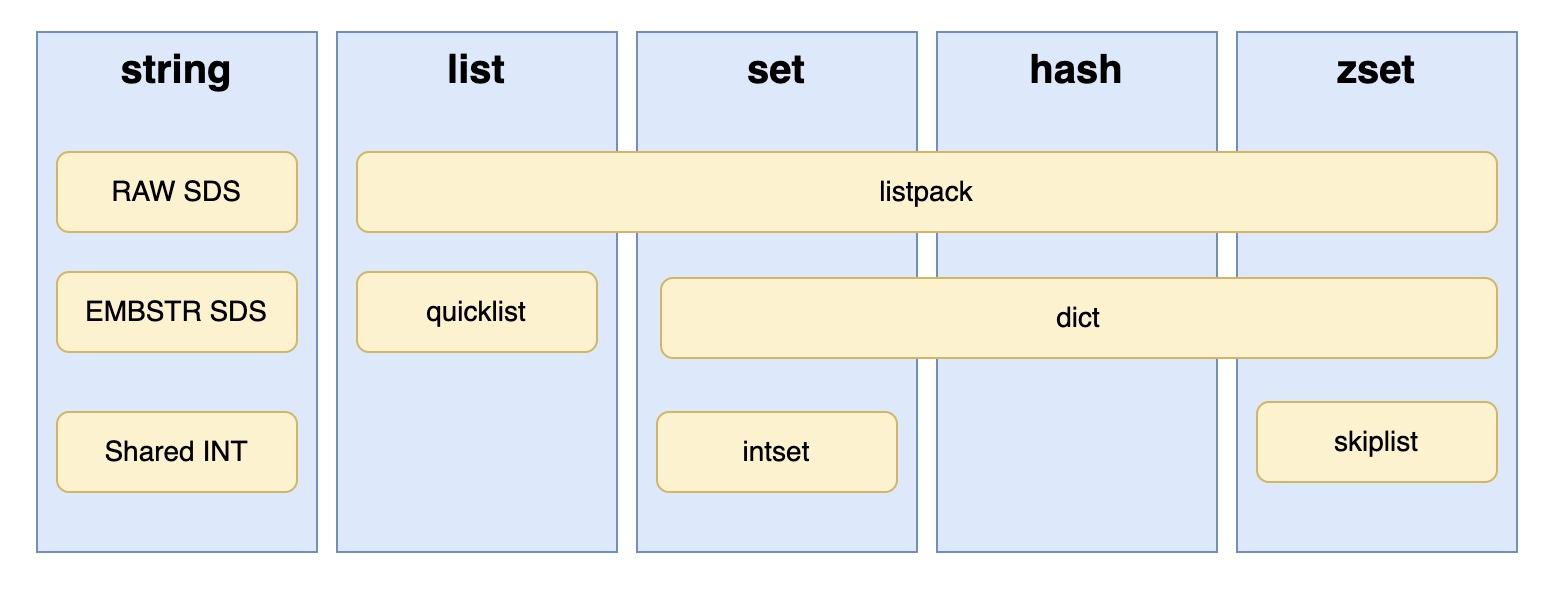
具体的,object->type 和 object->encoding 的对应关系为:
type=OBJ_STRING
字符串类型的 redis 对象使用的底层编码方式可能出现三种情况:
encoding=OBJ_ENCODING_INT:指向的内容是较小的整数时候使用encoding=OBJ_ENCODING_EMBSTR:需要保存长度较短的字符串(不超过OBJ_ENCODING_EMBSTR_SIZE_LIMIT=44字节),且没有被修改时候encoding=OBJ_ENCODING_RAW:其他情况都使用普通 SDS 存储
type=OBJ_LIST
-
encoding=OBJ_ENCODING_LINKEDLIST:较早期版本中可能会使用双端链表实现,现在已经废弃不再使用; -
encoding=OBJ_ENCODING_ZIPLIST:redis <=6.2 版本中,列表中元素较少的时候使用压缩列表来实现 -
encoding=OBJ_ENCODING_LISTPACK:redis >=7.0 版本开始,列表中元素较小时候使用紧凑列表来实现 -
encoding=OBJ_ENCODING_QUICKLIST:列表中元素较多时候使用快速列表来实现
type=OBJ_SET
-
encoding=OBJ_ENCODING_INTSET:集合中的元素都是较小的整数,并且集合元素数量较少时候使用整数集合实现 -
encoding=OBJ_ENCODING_LISTPACK:从 Redis >= 7.2 版本开始,集合中元素数量较小的时候使用紧凑列表来存储集合键的数据 -
encoding=OBJ_ENCODING_HT:集合中元素较多的时候使用字典来储存数据
type=OBJ_ZSET
-
encoding=OBJ_ENCODING_ZIPLIST:在 Redis <= 6.2 以下的版本,有序集合中元素较少时候使用压缩列表来实现 -
encoding=OBJ_ENCODING_LISTPACK:在 Redis >= 7.0 以上的版本中,有序集合中元素较少的时候使用紧凑列表来存储集合中的元素 -
encoding=OBJ_ENCODING_SKIPLIST:有序集合中元素较多的时候使用跳跃表来存储元素数据,但 redisObject->ptr 并不是直接指向跳跃表结构体,而是指向一个单独的zset结构体:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;zset 结构体中的 dict 用来存储有序集合键中成员 member 和分值 score 的对应关系,跳跃表 zsl 中按照分值 score 的顺序存放了各个成员 member 的值。
之所以单独设计一个 zset 结构体来挂载跳跃表结构,是为了提高有序集合键的查询效率,如果单独使用跳跃表来查询数据,时间复杂度为平均O(logN),最坏可能达到 O(N) 级别,通过单独保存的字典结构,可以快速从哈希表中获取到成员对应的分值数据,查询复杂度降为了 O(1) 级别,当然,单独记录哈希表又会占用更多的内存空间,这其实体现了 redis “以空间换时间”的思想。
type=OBJ_HASH
-
encoding=OBJ_ENCODING_ZIPMAP:较早期的版本中使用,现在已经废弃 -
encoding=OBJ_ENCODING_ZIPLIST:在 Redis <= 6.2 以下的版本中,哈希键中的元素较少的时候,使用压缩列表存储数据 -
encoding=OBJ_ENCODING_LISTPACK:从 Redis >= 7.0 版本开始,哈希键中元素较少的时候,使用紧凑列表存储数据 -
encoding=OBJ_ENCODING_HT:哈希键中元素较多时候,使用字典数据结构来存放数据
redisObject->lru
redis 对象中的 lru 字段是固定占用 24bit 长度内存,分别记录了对象最近使用的时间戳或者最近访问的频次数据。
-
当 redis 被设置启用了
maxmemory并且内存淘汰策略设置成 LRU 相关策略的时候,lru 字段记录的是一个24bit的最近访问的毫秒时间戳; -
当 redis 设置的内存淘汰策略是 LFU 相关策略,lru 字段前16bit记录了以分钟为最小精度的最近一次访问的时间戳,后8bit记录了根据特定算法计算出来的当前对象访问的频次值
lru 字段在 redis 内存超额时候,按照特定 LRU 或者 LFU 策略对数据库中键值对进行淘汰时候会使用或者更新。
redisObject->refcount
refcount 是当前 redis 对象的引用次数,redis 通过 refcount 字段来实现对象的回收和共享。
内存回收
当 redisObject 不再被使用时候,redis 对 redisObject->refcount 每次执行减1操作,当 refcount=0 时候会自动释放内存:
void decrRefCount(robj *o) {
if (o->refcount == 1) {
switch(o->type) {
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
case OBJ_MODULE: freeModuleObject(o); break;
case OBJ_STREAM: freeStreamObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o);
} else {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--;
}
}对象共享
上文提到,redis 服务在启动阶段,会创建足够多的 encoding=REDIS_ENCODING_INT 编码的的对象,这样,后续如果有整数数据需要被封装成对象时候,可以直接重复指向这些已经定义好的“共享对象”。
共享对象的 refcount 在创建阶段被设置为了 OBJ_SHARED_REFCOUNT,并且后续在执行内存回收时候,不会变更共享对象的引用计数的值。